
我們今天一共會整理google的5種Cloud API,以下針對類型先做個簡單整理:
| Google雲端上的API名稱 | 類型 | 用途 |
|---|---|---|
Cloud Vision API |
(image -> text) | 圖片辨識API |
Cloud Video intelligence API |
(video -> text) | 影片辨識API |
Cloud Speech API |
(audio -> text) | 語音辨識API |
Cloud Translation API |
(text -> text) | 語言翻譯API |
Cloud Natural Language API |
(text -> text) | 自然語言處理API |
第五章節的課程地圖: (紅字標記為本篇文章中會介紹到的章節)
Pre-trained ML APIs
Vision API in action
Video intelligence API
Cloud Speech API
Translation and NL
課程地圖
Cloud Vision API是google的圖片辨識的API,
可以讓我們使用單個REST API request就能得到圖片的各種檢測結果。
Giphy:Giphy是一個app,我們能在上面搜尋GIF,並在也可以分享這些動圖。
gif的裡面有可能包含文字,而它們可透過Vision API解釋gif裡面的內容,
並藉此改進搜尋結果。
他們使用的是Vision API裡面的OCR(Optical Character Recognition)功能,
這個功能讓它們可以從gif中提取出文字內容,用於幫助增進他們的搜尋體驗。
想要更了解Giphy怎麼做的,可以參考:https://engineering.giphy.com
| Vision API 功能名稱 | 用途 |
|---|---|
label detection |
可以告訴你這圖片是什麼 |
web detection |
在網路上搜尋相似圖片,並從這些搜尋結果中提取內容,回傳圖片更多相關資訊。 |
OCR (Optical Character Recognition) |
解析你圖片中的文字內容,告訴你圖片中哪裡有文字,甚至可以告訴你這是什麼語言。 |
Logo detection |
專門辨識公司logo用的 |
Landmark detection |
如果這圖片包含著常見的地標,他可以告訴你是什麼地標。 同時提供對應地標的經度、緯度 |
Crop hints |
可以幫助你裁剪照片,以符合你想要做的主題。 |
Explicit Content Detection |
檢測圖片中是否有不適當的內容。 |
※補充:
label detection
例如:你給他看大象的圖片,他會告訴你這是大象
以整體來說,Cloud Vision API可以提供上述所有功能的圖片內容檢測。
這些功能在任何地方皆很實用,而且特別像是社群網站檢測不適當圖片內容,
我們很難人工一張一張的檢測,這時候Vision API能夠幫助我們做初步的分類,
我們只需要簡單所有圖片的子集合即可。
自己的註:這邊講到的做法個人認為非常聰明,
他們並不是直接將Vision API認定不適宜的結果,
直接進行刪除的動作,而是先取這些圖片的子集合在"人工檢查"。
這樣兩階段的作法,
對於社群上的人:大幅的減少誤判機率
對於自己訓練的ML:如果我們認為這些圖片是適合的,
我們可以直接更改label,再次強化我們的ML判定。又能減少使用者不滿又能強化自己的ML模型,採用兩階段判定確實非常聰明。
Vision API有提供網頁版,在開始寫code串Vision API的功能前,
我們可以先到這網站測試自己想要偵測的圖片:https://cloud.google.com/vision/
可以先偷看串完Vision API會得到什麼結果。
(這邊也是先使用影片中的範例,有興趣的朋友可以自己嘗試。)
Step 1 : 首先我們先到網址中的紅框處,可以上傳自己的圖片。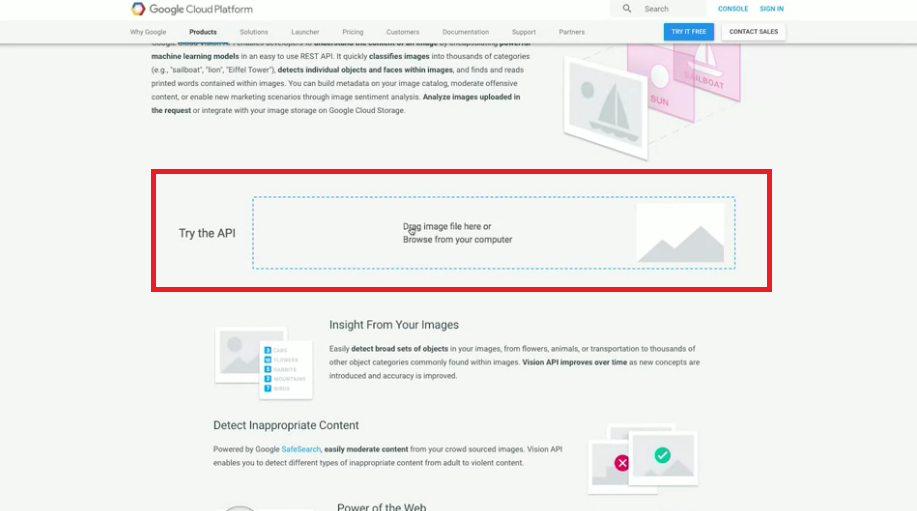
Step 2 : 得到我們圖片分析的結果。
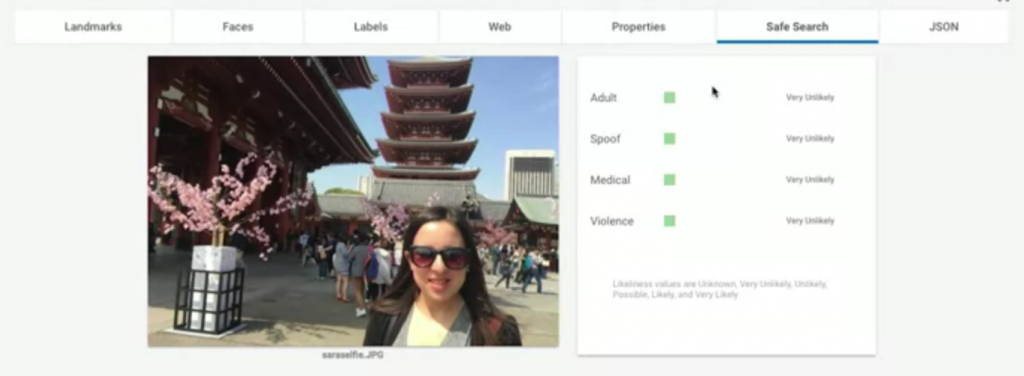
我們來看看我們可以得到什麼結果:
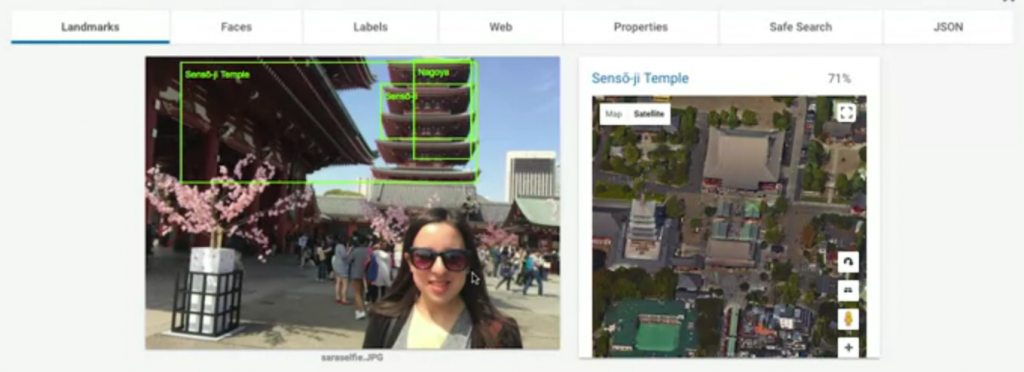
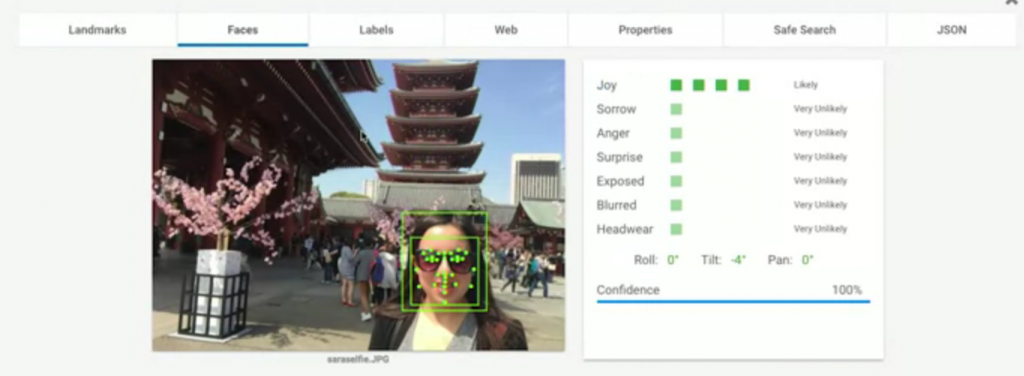
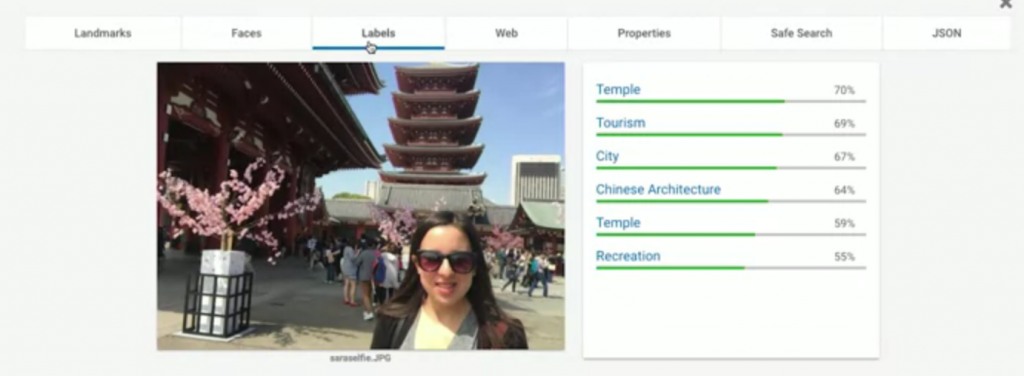
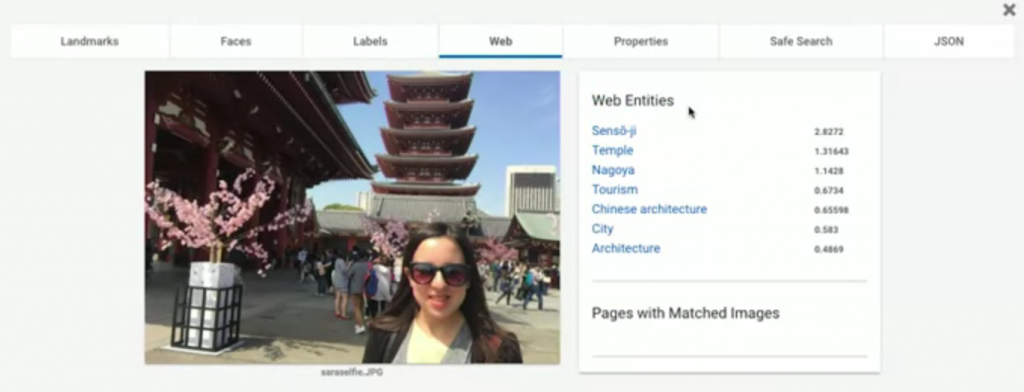
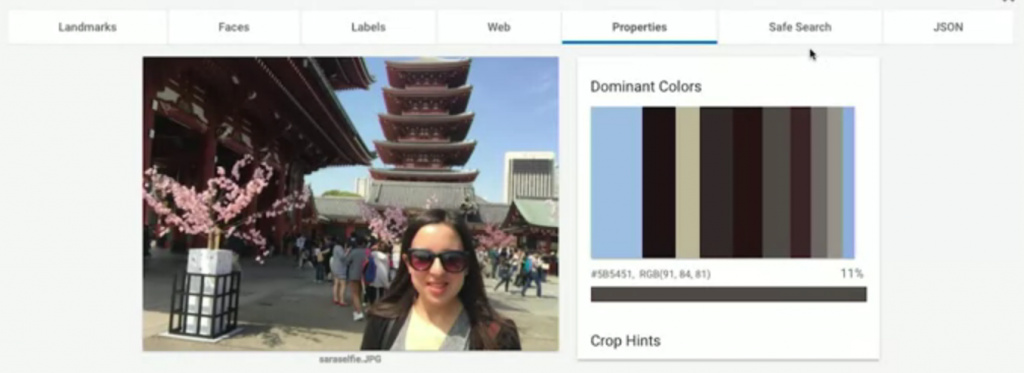
Landmarks: 顯示了這圖中的地標在哪(71%表示信心指數,有多肯定這答案的意思),我們還可以看到下方標出了實際上地圖的位置與衛星雲圖。Faces: 顯示了這張圖中哪裡有臉;還有辨識表情,像這張圖他認為圖片中的人很開心。Labels: 告訴你這張圖可能的組成元素,與這張圖的標籤。Web: 如果拿這張圖到網路上搜尋類似圖片,會得到什麼結果的分析整理。Properties: 告訴你這張圖片的主色調組成。Safe Search: 告訴我們這張圖片是否有不適當內容,主要分成四種判定標準
很明顯的,這張圖片都沒有包含以上的分類要素。
JSON: 將上面所有結果的內容包成JSON給你,也就是實際上串好API會拿到的東西。課程地圖
Video intelligence API是google的影片辨識的API,
可以讓我們分析一個影片內容,從一瞬間、一幀到一整個影片的分析都可以做到。

| Video intelligence API 功能名稱 | 用途 |
|---|---|
label detection |
他會告訴你這影片中可能有什麼(代表著他的label) |
Video & scene-level annotations |
從各個場景或整個影片"解釋"影片的內容,算上面功能的進階版 |
Shot Change Detection |
告訴你這個影片哪裡有(突然的)場景變化。 |
Explicit Content Detection |
檢測影片中是否有不適當的內容。 |
Regionalization |
使我們可以指定這個影片可以執行Video intelligence API的區域 |
※補充:
Video & scene-level annotations
自己的註:要"解釋"影片可以從很多個角度切入,
例如說一個場景可以解釋出一個意義,
scene等級的功能就是在做這樣的分析,而video等級的分析就是做整部影片的解釋。
與label detection不同的是,label只會告訴你有什麼,但不會告訴你意義(沒有"解釋")
Shot Change Detection
例如:如果你的影片從一個風景突然特寫到一個人,他會告訴你變化的時間點。
Video intelligence API一樣有提供網頁版,在開始串Video intelligence API前,
我們可以先到這網站測試自己影片的結果:https://cloud.google.com/video-intelligence/
(這邊也是先使用影片中的範例,有興趣的朋友可以自己嘗試。)
example 1 : 一部影片的分析
我們先示範上傳一個影片,上傳後我們可以看到google已經為這個影片做了許多標籤: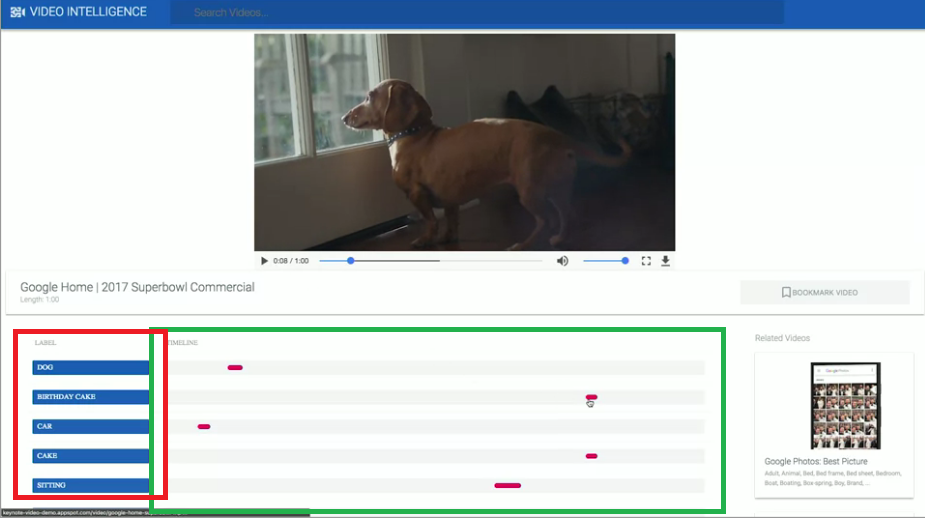
我們觀察結果,我們可以發現紅框處顯示了這影片中的label,
也就是Video intelligence API在這影片中找到的東西。
右側綠框處為這個label對應影片中的位置(秒數)。
以圖片中的上方影片正好有一隻狗出現,往下方找第一行DOG的label,
對應的紅色分布正是Video intelligence API偵測到有出現狗的片段。
以人工看影片的方式找出狗不是做不到,
但是會非常耗時且沒辦法大量快速的處理內容。
而且我們要完全確定答案的話,我們必須將整個影片都看過才行。
更何況如果我們不是要找狗而已,我們要找整個影片有哪些內容並記錄下來的話。
那人工處理這件事情的速度會非常慢。
我們可以用單一個REST API取得一個JSON格式的回覆結果,
這個畫面也是將JSON格式做一個視覺化的呈現,讓我們知道會拿到什麼東西。
example 2 : 多部影片的分析
這邊要提到的是對多部影片的分析,適用的情境例如:
我們是一家體育新聞公司,我們想要找尋棒球賽事的精采片段。
手動看手邊的每一部影片是一件耗時的工作,
我們如果使用Video API就可以很輕鬆地得到JSON結果。
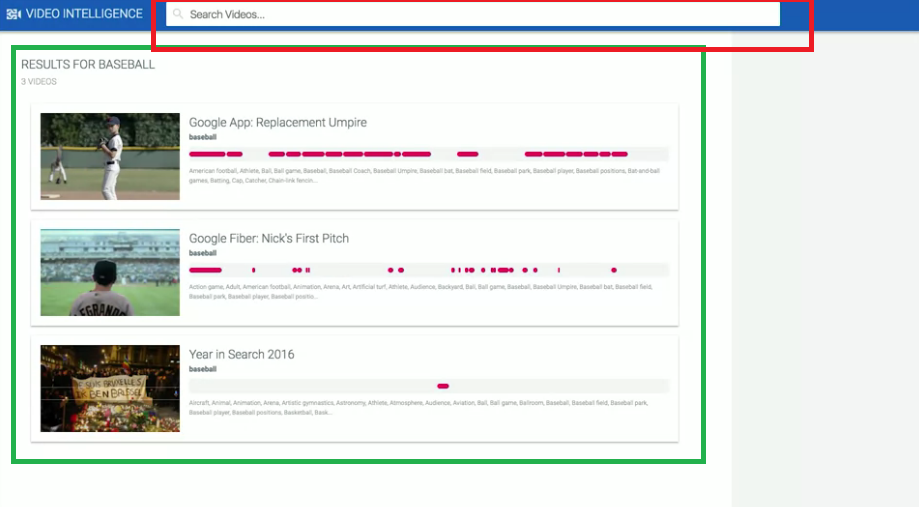
我們從上方紅框處搜尋baseball,我們就可以找到baseball的影片。
而下方會自動過濾出含有baseball的影片內容,以及baseball有出現的秒數。
而且我們只要對紅點處點擊一下,我們立刻可以看到那一段影片內容。
我們可以看見使用了Video Intelligence API,
只需要幾分鐘就能幫我們處理了人工觀看影片可能需要的數小時的工作時間。
課程地圖
Cloud Speech API是google的語音辨識的API,
他可以幫助我們從語音轉換成"超過100種語言"的文字稿。
| Speech API 功能名稱 | 用途 |
|---|---|
Speech to text transcription |
只要丟語音給Cloud Speech,就可以回傳語音的文字稿。 |
Speech timestamps |
可以讓你的文字稿具有能回查演講時間的功能(點文字就能跳到該語音段落)。 |
Profanity filtering |
過濾不適當的語音內容。 |
Batch & streaming transcription |
允許傳送一個完整的語音文件,或者也可以發送連續的語音串流。最後我們將會回傳一個完整的對應文字稿。 |
※補充:
Speech timestamps
也就是說,我們可以知道每一個字在speech中的開始與結束時間。
Cloud Speech API一樣有提供網頁版,
我們可以先到這網站測試自己語音的分析結果:https://cloud.google.com/speech
(這邊也是先使用影片中的範例,有興趣的朋友可以自己嘗試。)
而這裡我們著重在展示Speech timestamps的功能,我們先稍微解釋一下其運作的原理:

step1 : 從一個影片中提取出語音。
step2 : 將語音送進 Cloud Speech API 並得到文字稿與時間標記。
step3 : 我們將結果視覺化,在我們視覺化的UI中,我們可以直接搜尋文字稿對應影片的段落。
example 1 : 一部影片的分析
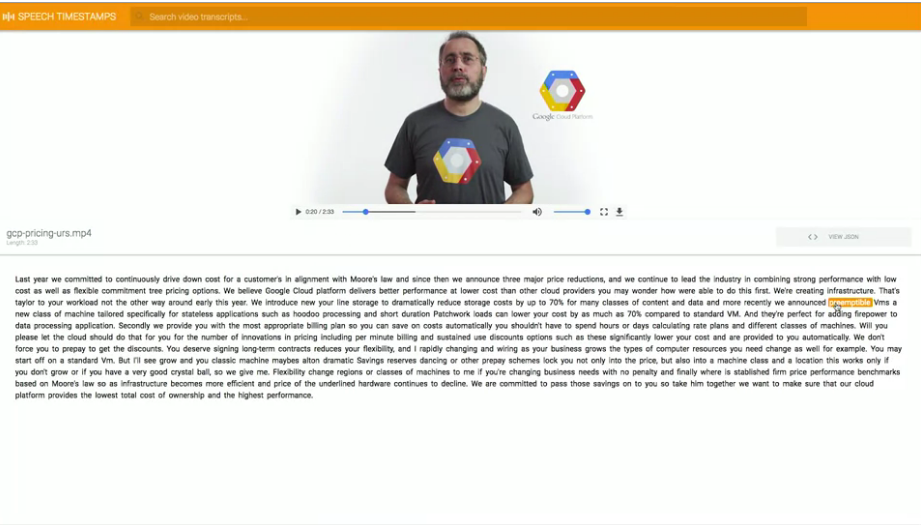
這個就是網頁顯示的結果,下方文字稿就是從上面影片內容擷取出的。
我們可以在下方任意點擊一段文字,就會直接跳到影片的該段落(如圖所示)。
example 2 : 多部影片的分析
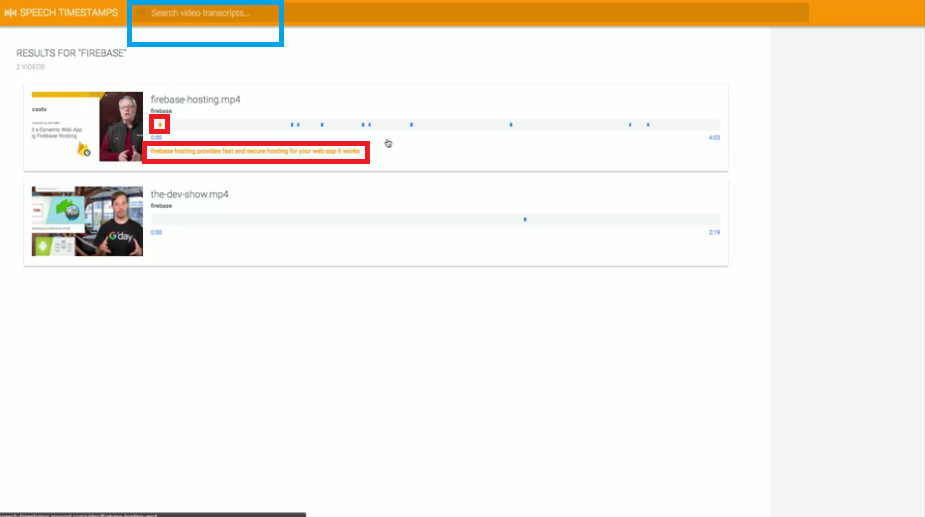
再來我們想要實現的功能是,在大量的演說影片中找到我們要的關鍵字。
我們回到主目錄,我們以搜尋Firebase作為示範,
我們可以先在上方藍框處搜尋,他會幫我們從我們所有的影片中找到符合我們的結果,
然後只要點擊對應的藍點處(如圖中的紅框處),就可以直接跳到該段影片有提到Firebase的內容。
當我們從語音得到文字之後,我們可能會想開始嘗試分析。
有一件可能必須做的事情就是我們得先試著翻譯他,Cloud Translation可以快速地幫助您完成。
| Translation API 功能名稱 | 用途 |
|---|---|
Translate text |
可以翻譯100多種不同的語言 |
Detect language |
可以偵測100多種不同的語言 |
※補充:
Detect language
也就是當你看不懂是哪個國家的語言的時候,他可以幫助你找到是哪個國家的。
Cloud Translation 最有名的應用就是 Google Translate,相信大家都不陌生,
Cloud Translation API能翻譯100多種不同的語言,
也就是說,如果我們現在想要做一個多國語言的服務,
自動偵測語言與翻譯語言能幫助你輕鬆地找到這是什麼國家的語言,並翻譯內容。
Cloud Translation API一樣有提供網頁版,
我們可以到這網站測試:https://cloud.google.com/translation
課程地圖
(Translation的課程內容應該在上一節,但這裡是依照google課程的名稱命名的,可能命名有誤。)
Cloud Natural Language是google提供的自然語言辨識API,
我們一樣可以利用單一的REST API request得到一段文字內容的理解。
| Natural Language API 功能名稱 | 用途 |
|---|---|
Extract entities |
可以從文章內容中提取entities(實體) |
Detect sentiment |
偵測這篇文章內容中或是句子的情緒,會告訴你情緒是正面還是負面。 |
Analyze syntax |
可以分析語法,了解更多文章的語言細節,或是提取文章中的部分內容。 |
Classify content |
可以將文章內容分類到不同類別。 |
Analyze syntax的demo與更詳細介紹以下,我們將先針對Analyze syntax做更多的介紹,
我們使用一個例句 "The natural language API helps us understand text."
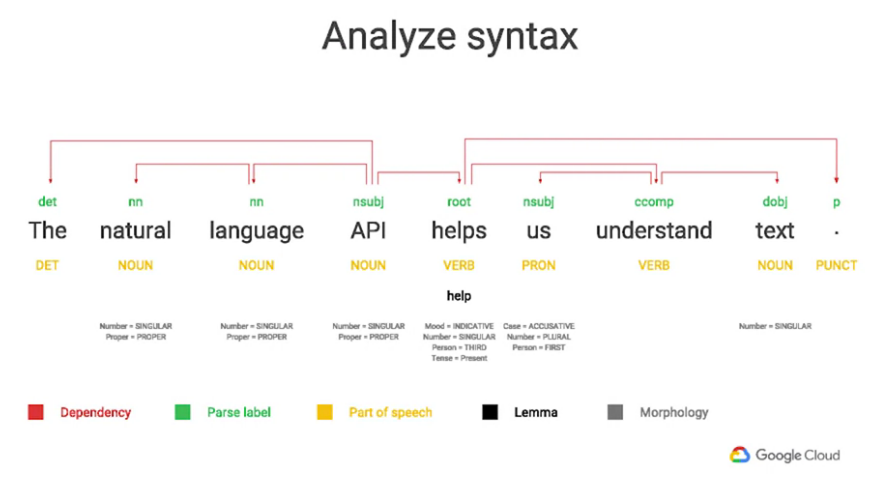
我們做了一個視覺化的圖片來使我們能更了解透過API回覆的JSON內容,
Dependency parse tree(紅色部分),這個的功能是將所有有關係的詞彙做相互關聯,
像是那些單詞可能與其他的單詞有關係。
Parse label(綠色部分),他會告訴我們每個詞在句子中的作用
例如,在這句話裡面 helps 是 root verb(主要的動詞),API是nominal subject(主要的主詞)
Part of speech(黃色部分),他會告訴我們每個詞在句子中的詞性(形容詞、名詞、動詞...)
Lemma(黑色部分),代表這個詞的canonical form(標準形式)
例如,在這句話裡面 helps 的 canonical form(lemma) 是 help
這個對於計算特定單詞用於描述某些內容,在文章中所出現的次數非常有用
你可能不希望在分析的過程中,helps 與 help 被當成兩個詞來分別計算,
這時Lemma就可以幫助你完成這件事情。
Morphology (灰色部分),可以分析這個詞的Morphology(詞法)例如:名詞有可數、不可數的特性...,動詞有是不是第三人稱單數之類的特性...
這個結果也會根據語言而有所不同。
Content classification的demo與更詳細介紹以下,我們將針對Content classification做更多的介紹,
我們拿一篇新聞文章來做分析,我們將這篇新聞的標題與第一句話丟進Natural Language API進行分類。

我們可以看到他返回的類別是baseball(上方紅框處),
我們再注意另外一件事,文章裡面並沒有提到過baseball這個詞,
但google告訴我們他有99%的肯定(下方紅框處)這篇文與baseball有關。
這個API的方法總共提供了700多種可用的類別可以使用。
這邊我們會提到一間公司使用各種不同的Natural Language API方法在他產品中的例子。
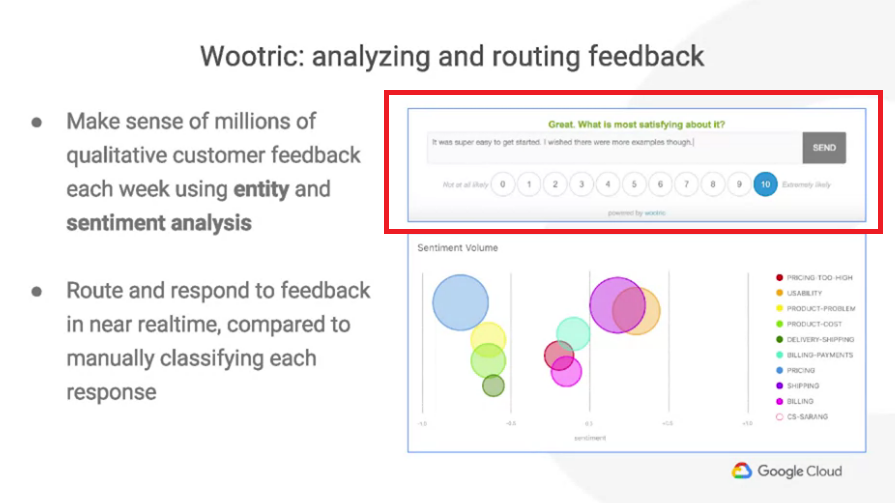
Wootric:一個客戶反饋的平台,他透過圖中紅框處幫助客戶收集使用者的回饋,
他們在自己應用中的各處放置這個方框,
並且要求用戶提供一個分數代表著它們的使用體驗與覺得這個應用最特別的地方。
0-10的分數很容易理解,但是如果是開放式的回饋(自己填文字的)就比較難快速理解(需要時間消化內容)。
而這個就正是他們使用natural language API的地方,
它們使用sentiment analysis來分析這個人的文字回覆情緒是否與他們提供的數字分數吻合,
然後他們使用entities與syntax analysis取解析出最關鍵的內容(entities),
並直接反饋給適當的對象,就可以做即時的處理,而不用派一個人手動的逐條閱讀回饋內容才反饋。
例如:他們可能遇到對可用性感到憤怒的使用者,他們可以及時反應給適當的人,請他做即時的處理。
而如果沒有這樣做,我們會需要一個人手動的閱讀每一條回饋內容,並一個個反饋給適當的對象。
Cloud Natural Language API一樣有提供網頁版,
我們可以先到這網站測試自己文字分析結果:https://cloud.google.com/natural-language/
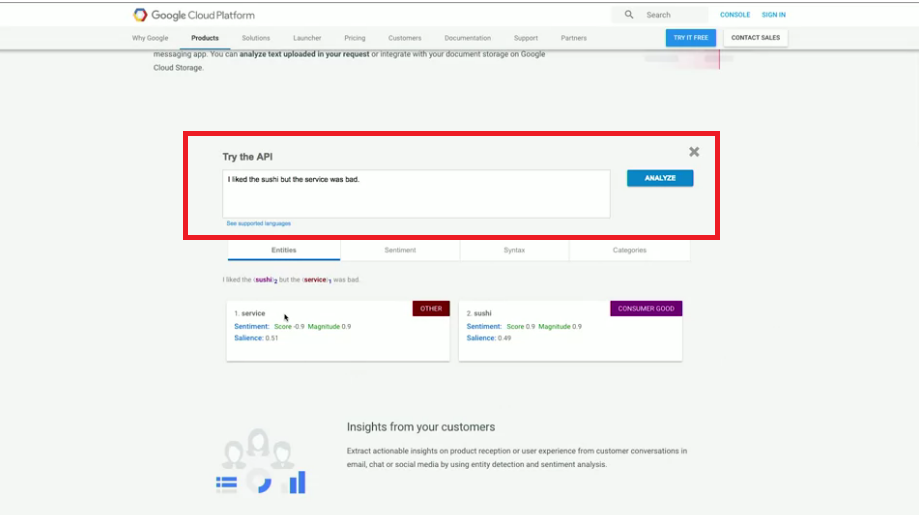
紅框處可以打入自己想要的句子,
我們以影片中句子作為例子:"I liked the sushi but the service was bad."
這是從某個餐廳的評論找下來的,假設我們是經營餐廳的人,每天我們可能會收集很多評論,
我們不會想一句句的分析每個評論,我們可能只想找最正面與最負面的評論。
我們來看看Cloud Natural Language API分析的結果:
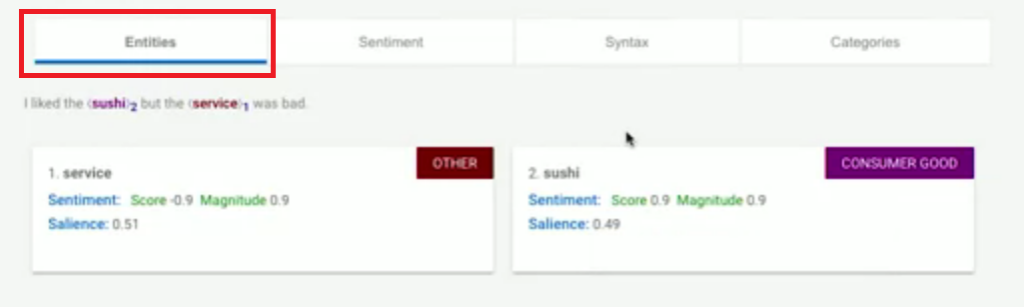
Entities:從這個句子的結果中,我們看到他從我們的句子中分析出了兩個entities(實體),service與sushi,並且還能夠從這兩個實體中分別分析情緒。natural language API 返回的情緒值介於-1到1,表示情緒的負面與正面。
我們可以看到service的得分為-0.9,幾乎完全是負的,表示顧客認為服務很差。
我們再來看sushi的得分為0.9,幾乎完全是正的,表示顧客非常滿意壽司。
這樣的個別實體分析是非常有價值的,整句話的情緒分析做不到這樣的細節分析。
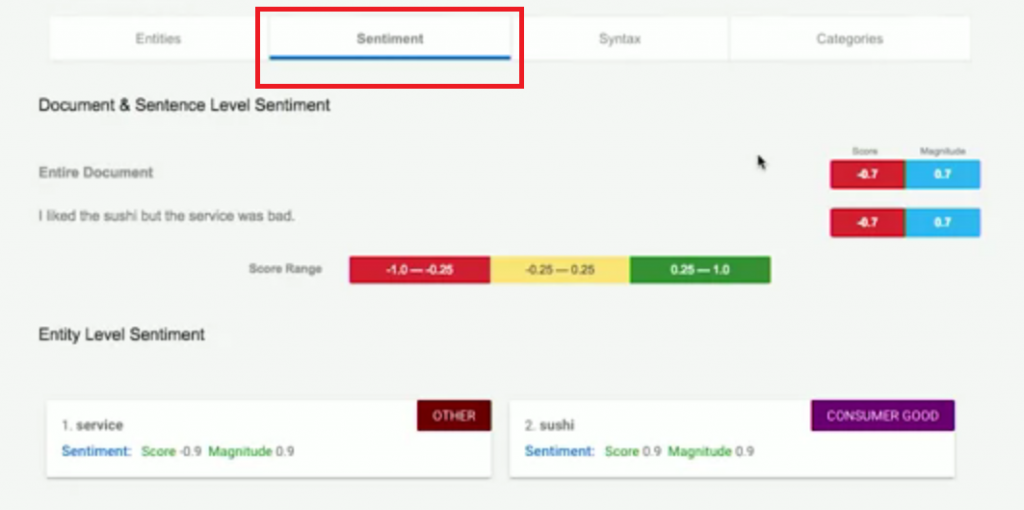
Sentiment:我們再來看到整句話的情感分析,也能同樣看到上方的單個實體分析結果。不過這個例子特別的地方在於,我們針對單個實體分析情緒,
比起分析整句話的情緒,能得到更多有用的資訊。
(sushi好而service不好,整句話只能知道是不好的。)
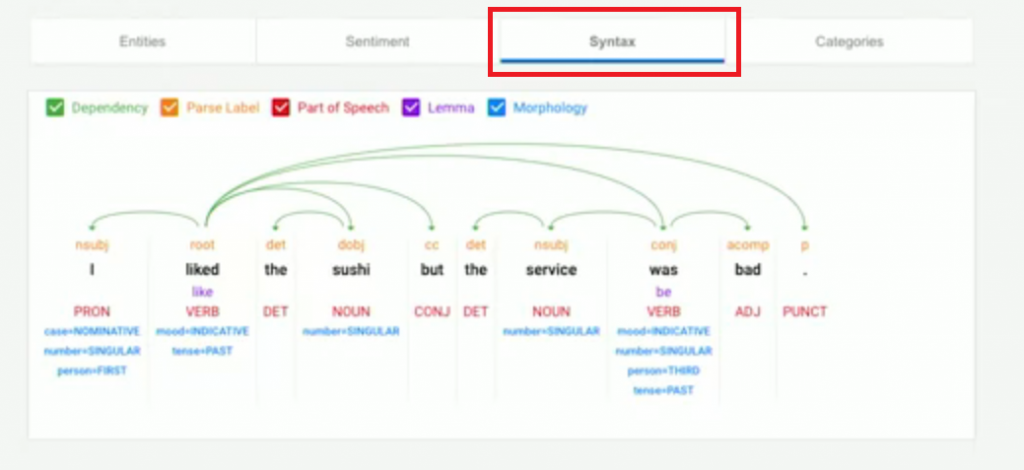
Syntax:可以幫我們分析這句子的結構,因為上面已經有詳細demo過了,這邊只展示結果。
Categories:可以看到這句話是屬於哪一種分類。影片中沒有展示。
但我有自己試了,原來是找不到結果XD (是因為這樣才沒放在影片中嗎XD
)
回傳的結果會是 "No categories found. Try a longer text input."
照這句話的意思看來,可能是資訊量不足,還沒辦法做分類,
上方的例子畢竟是用一篇新聞的句子才能找到結果,也許是因為這句話能提供的資訊還太少吧。
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉

 iThome鐵人賽
iThome鐵人賽